前言0 摘要1 Introduction2 相关工作2.1 文本对话回复生成2.2 Text-to-Image 生成3 Problem Formailzation4 Approach4.1 多模态 Tokenization4.1.1 文本 Tokenization4.1.2 图像 Tokenization4.2 低资源学习模型4.2.1 文本对话回复生成器 (Textual Dialogue Response Generator)4.2.2 Text-to-Image 转换器 (Text-to-Image Translator)4.2.3 学习细节5 实验5.1 数据集5.2 评价指标5.3 实现细节5.4 Baselines5.5 评价结果5.6 消融实验5.7 案例分析5.8 讨论6 结论
——ACL 2022
前言
论文标题:Multimodal Dialogue Response Generation 论文网址:https://aclanthology.org/2022.acl-long.204/ 收 录 于:ACL 2022
省流版:
动机:
多模态开放域对话的回复生成,目前研究者们基本都是围绕检索任务进行研究,很少涉猎 生成任务
- 检索模型会受训练数据集的制约,无法在新场景下获得良好表现
- 多模态对话生成任务除文本生成外,还涉及难度较大的图片生成
多模态对话 数据集 由于人工构造难度大,真实数据涉及隐私等原因,可用数量很少
图像与文本难以 联合表示 的问题依然存在,图片会含有大量难以用文本表示的抽象信息

Figure 3:提出的方法的抽象逻辑。实线表示存在大规模训练集对生成模型进行预训练,虚线表示只有很少的训练样例可用,“×” 表示生成质量差。其中

Figure 2:本文多模态对话回复生成模型的整体结构。Textual Dialogue Response Generator 将文本对话上下文
方法:
虽然文本对话+图片的相关数据集较少,但图片描述+图片的数据集很多
- 对于文本回复生成,采用常规的开放域 对话回复 生成方法
- 对于图片的生成,采用间接生成的策略,先依据对话文本生成 图片描述,再根据图片描述文本生成图片
采用基于 Transformer 的端到端模型 (Divter),分别单独预训练两个子模型
- Text-to-Text 模型,依据对话文本生成文本回复和图片描述
- Text-to-Image 模型,依据图片描述生成图片
实验结果及结论:
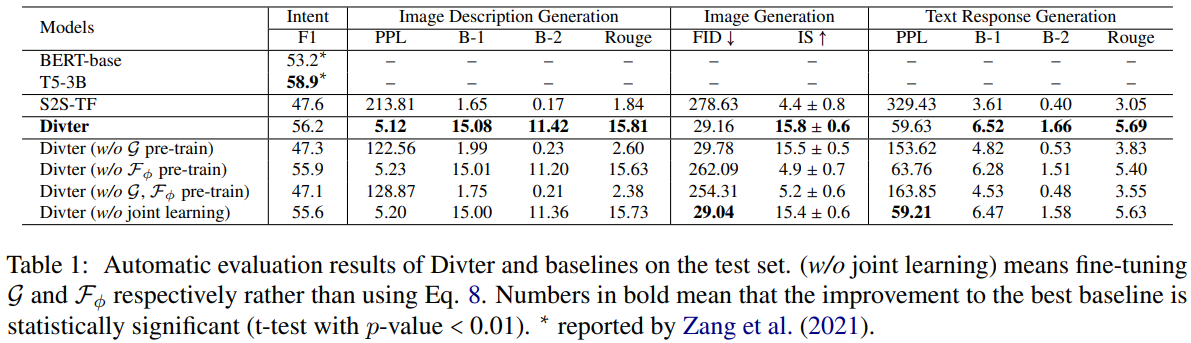
机器评价
- 文本生成任务采用 PPL、BLEU 和 Rouge 作为评价指标,图片生成任务采用 FID 和 IS 评价图片质量
- Divter 模型在图片描述生成、文本回复生成和图片生成三个任务上均取得了高于 baseline 的表现
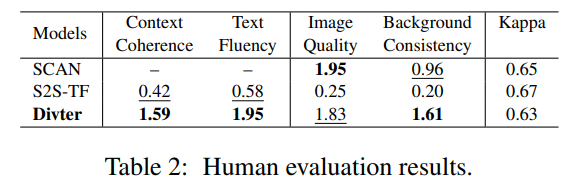
人工评价
- Divter 模型在文本和图片方面都获得了更高的人工评价分数
0 摘要
图像响应已经被认为是智能会话代理的一项重要能力。然而,现有的研究主要集中在基于检索的多模态对话模型,而忽略了生成方法。
为了填补这一空白,作者首先提出了一个新的任务:多模态对话响应生成 (multi- modal dialogue response generation,MDRG) —— 在给定的对话上下文中,一个模型需要生成文本或图像作为回复。
学习这样的 MDRG 模型通常需要包含文本和图像的多模态对话,而这些对话很难获得。出于实践中的挑战,我们在一个自然的假设下考虑 MDRG,即只有有限的训练样例可用。在这样的一个低资源环境下,我们设计了一个新的会话代理 Divter,以便从整个生成模型中分离出依赖于多模态对话的参数。通过这种方法,模型的主要部分可以分别从大量 纯文本对话 和 文本-图像对 中学习,然后只需要几个训练样例就可以很好地拟合整个参数。
大量实验表明,该方法在自动评估和人工评估方面都达到了 SOTA,并能生成信息丰富的文本和高分辨率的图像回复。
1 Introduction
近几十年来,随着实时通信技术的发展,网络对话的媒介也从单纯的文本转变为多种视觉模态 (如图像、GIF动画、短视频)。与现实中通过通信工具 (如 Facebook,WhatsApp,WeChat) 进行交流类似,一个优秀的智能会话代理应该不仅能够用纯文本自由对话,还要具备感知和分享真实视觉物理世界的能力。
尽管最近一些大规模预训练纯文本对话生成模型,如 DialoGPT, Blender, Meena,表现出了优异的性能,但他们仍然不能完全依赖纯文本来完全模拟视觉感知的丰富体验。最近,各种 vision-language 任务被引入并引起广泛关注,如 视觉问答 (visual question answering),图像描述 (image captioning),基于图像的对话 (image-grounded dialogue)。
- DialoGPT: 论文标题:DIALOGPT : Large-Scale Generative Pre-training for Conversational Response Generation 论文网址:https://aclanthology.org/2020.acl-demos.30/
- Blender 论文标题:Recipes for Building an Open-Domain Chatbot 论文网址:https://aclanthology.org/2021.eacl-main.24/
- Meena: 论文标题:Towards a Human-like Open-Domain Chatbot 论文网址:https://arxiv.org/abs/2001.09977

在人类对话中,图像很容易表现出丰富的视觉感知,这是纯文本难以表达的。 如 Figure 1 所示,至少在三种情况下需要图像:
- 另一个说话者对只有你见过的物体知之甚少(例如,在第一幅图像中的 colorful Burano);
- 分享物品的更多细节 (例如,在第二幅图像中的红酒和意大利面);
- 表达你对某一特定时间的情绪 (例如,在第三幅图的开心)
现有的一个相关任务是图片分享,其目的是基于文本上下文来选择和分享图像,这是一个具有挑战性的任务,需要模型理解由人类想象补充的背景故事,而不是像以前工作那样定位相关的视觉目标或明确提到图像中的主要可见内容。PhotoChat: A Human-Human Dialogue Dataset With Photo Sharing Behavior For Joint Image-Text Modeling 提出一种基于检索的方法来解决上述挑战。然而,基于检索的方法在特定领域受到预先构建的会话历史存储库的大小的限制,特别是在历史对话中没有涉及的长尾 (long-tail) 上下文,其中检索系统的图像回复集也是固定的。另一方面,一个更好的方法是相应地生成一个新的回复。
本文提出了一个新的问题:多模态对话响应生成(Multimodal Dialogue Response Generation, MDRG),即在给定对话上下文的情况下,模型不仅要生成纯文本回复,还要具有生成多模态回复的能力 (例如,同时包含图像和文本)。
作者认为在实际应用中仍然存在一些障碍,因为:
- 复杂的神经端到端结构将过拟合极少的标注好的训练数据 (例如,少数现有的 10k 多模态对话)。当讨论训练数据领域外的话题时,其性能急剧下降。
- 由于人力资源昂贵,为一个新的领域收集足够的训练数据并不容易。
基于以上事实,我们进一步将 MDRG 的假设扩展到只有少量多模态对话可用的低资源环境中。
为了解决上述问题,我们的主要思想是通过分离文本回复生成和图像回复生成,使依赖于多模态对话的参数变得小且独立,从而从纯文本对话和更容易获得的 <image description, image> pairs 中学习生成模型的主要部分。 具体来说,作者提出了 Divter,一个由大规模视觉世界体验驱动的新型会话代理。
Figure 2:本文多模态对话回复生成模型的整体结构。Textual Dialogue Response Generator 将文本对话上下文
如 Figure 2 所示,Divter 由两个基于 Transformer 的组件组成:一个多模态对话回复生成器,和一个 text-to-image 转换器。Divter 将对话上下文作为输入,生成文本序列,该序列可以包含一个文本回复或一个文本形式的图像描述,也可以包含两者。text-to-image 转换器将以上的图像描述作为条件,生成逼真连续的高分辨率图像。这两个组件都是独立的,具有相反的知识,因此可以分别使用大量的纯文本对话和 <image description, image> pairs。 端到端的 Divter 依赖于以元组形式构造的多模态对话: (dialogue context, text response / <image description, image>),但是这两个组件的联合学习和评估仅需要一些训练样例,具体取决于特定领域。
本文的贡献有三个方面:
- 这是第一项在多模态对话回复生成的工作。作者在低资源环境下探索这个任务,其中只有一些多模态对话被假定为可用。
- 本文提出 Divter,一个新颖的会话代理,它可以有效地理解对话上下文并生成信息丰富的文本和高分辨率图像回复。
- 在 PhotoChat Corpus 上进行大量实验证明了 Divter 的有效性,它通过纯文本对话生成模型和基于检索的图像分享方法获得了显著的改进。
2 相关工作
2.1 文本对话回复生成
文本开放领域对话的 end-to-end 回复生成受到神经 sequence-to-sequence 在机器翻译上的成功启发。在这个基础结构之上,vanilla encoder-decoder 方法被广泛研究,以应对开放域对话系统中的关键挑战,包括改善回复的多样性、建模会话上下文、控制回复的属性、对某些特定人物角色的偏置、将额外知识纳入生成器、构建通用的预训练 agent。不同于以往对开放域对话回复生成的研究,本文的工作主要是对多模态回复生成的研究。
2.2 Text-to-Image 生成
在 text-to-image 生成的研究中,许多工作都得到了广泛的研究。
Generating Images from Captions with Attention 展示了 Draw 生成模型。
DRAW: A Recurrent Neural Network For Image Generation 可以从自然语言描述生成图像。
Generative Adversarial Text to Image Synthesis 提出了生成对抗网络来提高图像的保真度。然后一些改进方法继续优化生成架构:
Plug & Play Generative Networks: Conditional Iterative Generation of Images in Latent Space 提供了相关激活最大化方法的统一概率解释,以产生更高分辨率的高质量图像。
使用具有大范围的掩码比率的均匀 mask,并将合适的预训练数据集与合适的物体对齐。
X-LXMERT: Paint, Caption and Answer Questions with Multi-Modal Transformers 和 CogView: Mastering Text-to-Image Generation via Transformers 采用基于 Transformer 的方法,将文本和图像 token 自回归地建模为单个数据流。
对于这种多模态回复生成场景,作者使用文本形式的图像描述来连接文本对话生成和 text-to-image 生成模型,其中图像描述是前者的输出,是后者在低资源环境下的输入。
3 Problem Formailzation
假设有数据集
4 Approach
本章节首先阐述了用于多模态对话的统一的 tokenization 方法。 然后介绍了低资源场景下多模态对话回复生成模型 (Divter) 中的两个重要组成部分:(1) 文本对话回复生成器; (2) text-to-image 转换器。 Figure 2 展示了 Divter 的整体框架。
4.1 多模态 Tokenization
为了学习一个多模态生成模型,我们首先要对文本和图像的统一表示进行建模。 受DALLE 和 VQGAN 的成功启发,为了利用高度表达的 Transformer 结构来进行 text-to-image 的生成,我们需要以序列的形式表达图像,类似于我们通常对纯文本 tokenization 所做的事情。
- DALLE: 论文:Zero-Shot Text-to-Image Generation
- VQGAN: 论文:Taming Transformers for High-Resolution Image Synthesis 讲解:详解VQGAN(一)| 结合离散化编码与Transformer的百万像素图像生成 有关后文中 codebook 的概念。
4.1.1 文本 Tokenization
文本的 tokenization 已经得到了很好的研究,例如 BPE。本工作使用 50257 BPE-endoded tokens 和 Transformer 的分布式 embedding,对对话中的文本进行建模。
4.1.2 图像 Tokenization
图像的 tokenization 是一个离散 Auto-Encoder (VQGAN, https://github.com/CompVis/taming-transformers)
因此
4.2 低资源学习模型
用单一的 sequense-to-sequence 模型学习一个有效的多模态生成模型往往需要大量的训练样例。然而,由于社交媒体上的隐私原先和昂贵的人工费,导致只有很少的多模态对话可用。
Figure 3:提出的方法的抽象逻辑。实线表示存在大规模训练集对生成模型进行预训练,虚线表示只有很少的训练样例可用,“×” 表示生成质量差。其中
另一方面,如 Figure 3 所示,存在大量的开放的纯文本对话和大量的 <image description, image> pairs 的数据集:
- 纯文本对话:例如,Reddit comments,表示为
- <image description, image> pairs:例如,YFCC100M,表示为
基于以上事实和在 MDRG任务中的低资源挑战,作者将生成式 text-to-image 转换引入到纯文本开放域对话回复生成中。更具体地说:
- (i) 如果多模态对话上下文包含一个图像,我们就用它的描述来代替原本的图像,形成一个纯文本的语境,并将这个上下文作为纯文本对话生成模型
- (ii) 如果需要生成图像作为回复的一部分,我们可以先用
(i) 和 (ii) 都可以独立学习,这成为用大的
通过这种方法,当前的目标是学习一个具有
Figure 2 阐述了 Divter 的结构。该模型又两个部分组成:一个文本对话回复生成器
4.2.1 文本对话回复生成器 (Textual Dialogue Response Generator)
文本对话回复生成器
推理: 给定一个新的文本对话上下文
4.2.2 Text-to-Image 转换器 (Text-to-Image Translator)
text-to-image 转换器
然后将 tokenize 后的
训练一个自回归 Transformer 来模拟文本和图像 token 的联合分布,生成器的 loss 被定义为:
推理:给定一个描述
4.2.3 学习细节
定义
其中
讨论:在这项工作中,我们主要集中在整合文本和图像回复生成,但我们提出的方法实际上提供了一个低资源 MDRG 的通用解决方案,其中目标模态可以是 gif、视频或语音等。要做到这一点,我们只需要修改 text-to-image 转换器,使其与特定的模态类型兼容,然后预先训练一个新的 text-to-<target modality> 转换器。
5 实验
5.1 数据集
在 PhotoChat 数据集上进行了广泛的实验来评价 Divter 的性能,这是一个由 10917 个图像和 12286 个对话组成的多模态会话数据集,每段对话都与会话过程中分享的用户图像配对,每幅图像都与其文本描述配对。数据集已被拆分为 10286 个训练集、1000 个验证集和 1000 个测试集样例。更多细节参考附录A.1。

5.2 评价指标
使用自动评价和人工评价进行评估。
对于自动评价,主要关注四个方面:
- 图像意图预测,该任务的目标是预测在给定的背景下是否应该在下一轮生成一幅图像;
- 文本描述生成;
- 图像生成质量;
- 文本回复生成。
对于 (1),遵循 PhotoChat: A Human-Human Dialogue Dataset With Photo Sharing Behavior For Joint Image-Text Modeling 的观点,将问题制定为二分类任务,使用 F1 作为评价指标;对于 (2) 和 (4),使用 PPL,BLEU、Rouge 和 F1; 对于 (3) 遵循 DALLE 的观点,使用 Frechet Inception Distance (FID) 和 Inception Score (IS)。
对于人工评价,随机抽取 200 个对话上下文,并从 PhotoChat 中生成 Divter 和 baselines 的回复。要求 3 位人类注释者从以下 4 个方面对回复质量进行评分,评分范围为
- 语境连贯:文本回复是否与语境连贯;
- 文本流畅性:文本回复是否自然、流畅;
- 图像质量:图像回复的质量 (包括清晰度和完整性);
- 图像背景一致性:对于每一个对话,我们选择 top-8 生成/检索出的图像组,并要求注释者判断该组是否与对话背景一致。
定性评估如 Figure 5 所示。本文展示了 3 个注释者的平均分数,分数越高越好。


作者还将纯文本 Divter 和多模态 Divter 分别与 DialoGPT 进行比较。纯文本 Divter 意味着我们在解码阶段屏蔽词汇表中的
5.3 实现细节
对于文本对话回复生成器
对于图像 tokenizer
对于 text-to-image 转换器
在联合学习中,先训练
A.3 More Implementation Details
CLIP 模型根据图像与描述的匹配程度给出评分,并利用 CLIP 对生成的256个样本进行重新排序,选择最佳的图像作为最终的回复。为了获得高质量的训练集,丢弃了描述中以 “The photo has your * #” 为前缀的样例,其中 “*” 包括 “mom”,“dad”,“daughter”,“sister”,“uncle” 等,“#” 是一个人的名字。 为了从ImageNet 中构建 text-to-image 转换器
实现代码:
- 图像 Auto-Encoder:https://github.com/CompVis/taming-transformers
- 文本对话回复生成器:https://github.com/microsoft/DialoGPT
- Text-to-Image 转换器:https://github.com/lucidrains/DALLE-pytorch
5.4 Baselines
选择两个预训练模型 BERT-base 和 T5-3B 作为 baseline 来衡量 5.2节 中的 “图像意图预测” 任务。它们将文本对话上下文作为输入,预测 “一张图像是否会在下一轮被分享” (在给定的背景下是否应该在下一轮生成一幅图像)。
SCAN:该模型获取图像区域和文本 tokens 之间的相互作用来推断 image-text 的相似性,SCAN 在 PhotoChat 上实现了 “图像检索” 任务的 SOTA。
S2S-TF 是一个具有 24 层 Transformer 的单一的 sequence-to-sequence 模型,本文只使用 PhotoChat 来训练这个多模态生成模型。
5.5 评价结果
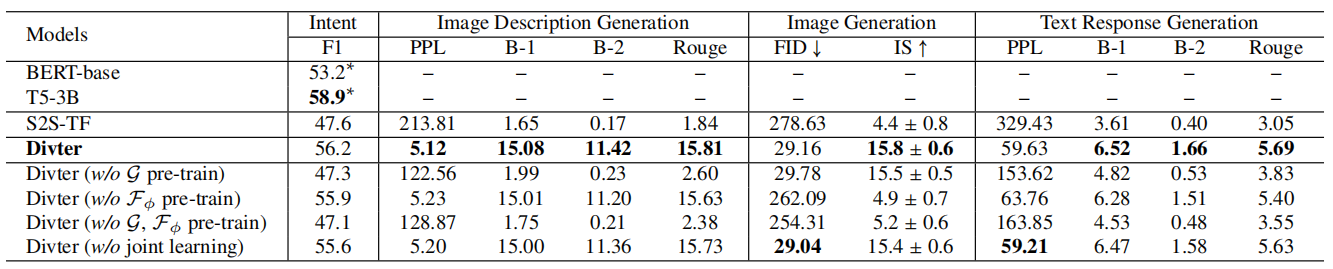
Table 1:测试集上 Divter 和 baseline 的自动评价结果。(
如 Table 1 所示, Divter 不仅获得了与基于检索的图像回复意图预测的 SOTA 模型相当的性能,而且在所有生成部分的评价指标中都获得了优越的性能。这标志着 Divter 能够准确地判断在给定对话上下文时生成图像回复的时机,并生成语上下文连贯的文本回复,也能够生成高质量的图像回复。Divter 与未进行预训练的 baseline (如 S2S-TF,Divter 的变体) 之间显著的性能差距表明了作者提出的学习策略的优越性。

Table 2 展示了人工评价的结果,Divter 在大多数方面都由于 baseline。

Table 3 的对比结果表明:
- Divter 在纯文本回复生成方面可以达到与 DialoGPT 相当的性能;
- 与纯文本对话模型 DialoGPT 相比, Divter 生成的多模态回复在对话体验和吸引力上有了显著的提高。
5.6 消融实验
Table 1:测试集上 Divter 和 baseline 的自动评价结果。(
如 Table 1 所示,所有变体都在大多数评价指标中的性能更差。

Figure 4:在 PhotoChat 测试集中,输入相同的上下文对图像生成的各种变体进行定性评估。第1列:Divter。 第2列:Divter
为了更直观的比较,定性评估结果也如图4所示。 特别是,消融研究的定量和定性结果都验证了:
- 预训练对于低资源多模态对话回复生成至关重要,因为当训练数据较小时,从预训练中删除任何分量都会导致性能下降;
- 在对图像生成性能的影响方面
- 联合学习对于 Divter 也有贡献,表明利用文本上下文和视觉图像的集成学习比任何单一的学习都要好。
5.7 案例分析

Tabel4:PhotoChat 测试集样例。在每个例子中,前缀为 “A” 或 “B” 的是给定的上下文,蓝色文本是 Divter 生成的文本描述,左边的图像和红色的回复是由 Divter 生成,右边的图像是 ground-truth 图像。
为了进一步研究 Divter 生成的多模态回复的质量,在 Tabel4 中展示了 PhotoChat测试集上的两个例子。第一个给定的上下文是关于 “ice-cream” 的,第二个是关于 “honey bee” 的。Divter 不仅可以生成与背景一致的逼真的高分辨率图像,而且可以生成基于该图像的信息丰富的文本回复。另外,生成的高质量图像与真实世界的 ground truths 相媲美,证明了 Divter 的实用性。
5.8 讨论
优于基于检索的方法
为了进一步研究和比较 Divter 和基于检索的方法的泛用性,作者还获取了在给定相同上下文的条件下,从 Divter 生成的 top-10 的图像和从 SCAN 模型中等效检索出来的图像。如 Figure 5 所示,一方面,生成的图像的多样性和丰富性是令人满意的,另一方面,这些检索的结果往往和对话背景不一致。例如:
- 在第二个例子中,对话是在讨论 “coffee”,但检索到的图像包含一些不相关的物体,如 “milk”,“cake”,“dog”,和 “snack”。
- 在第三个例子中,由于训练和检索空间中几乎没有 ”curtain“,所以所有的检索结果都是错的。
这表明基于检索的方法在特定领域的性能收到预先构建的会话历史存储库规模的限制,特别是在低资源的情况下。此外,本文提出的基于生成的方法展示出了更好的泛化能力,以解决低资源的挑战。
6 结论
本文研究了低资源环境下的多模态对话回复生成问题。为了克服新任务和训练数据不足带来的挑战,提出了一种神经会话代理 Divter,它将 text-to-image 生成与纯文本对话回复生成结合起来,其中大部分参数不再依赖于训练数据,而是可以从大规模文本开放域对话和<image description, image> pairs 中估计。大量的实验表明,Divter 在自动和人工评价方面达到了 SOTA。在未来,作者将探索更高效的方法,为回复生成注入更多的模态。